文档解析节点
什么是文档解析节点?
文档解析节点是您在 Magic Flow 中处理各类文件和数据源的"入口",它就像一个智能阅读器,能够读取和理解不同格式的文档内容,将原始文件转换为后续节点可以处理的文本数据。无论是本地上传的 PDF、WORD 文件,还是网络上的网页内容,文档解析节点都能帮您提取出有价值的信息。
图片说明:
文档解析节点界面主要由"显示名称"、"添加参数"选项、"参数值"和"表达式"设置区域组成。用户可以在此配置数据来源、文件类型及解析方式等参数。 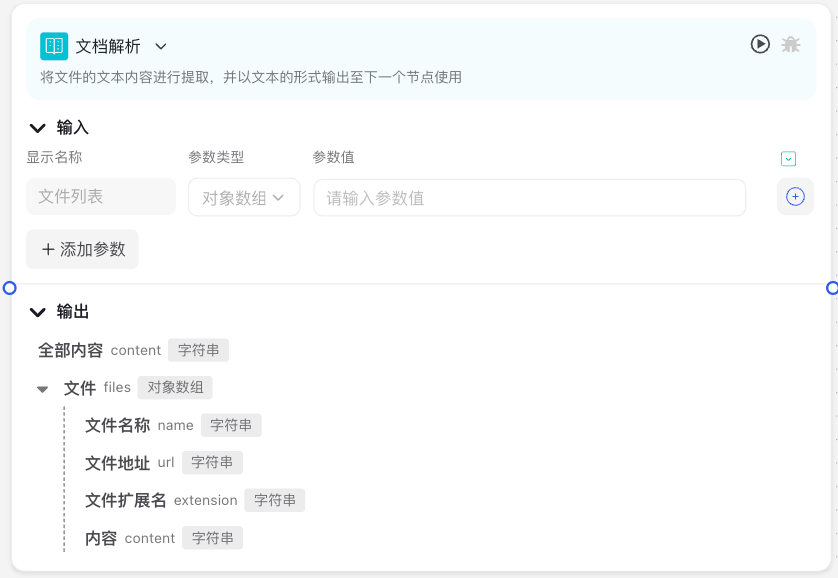
为什么需要文档解析节点?
在构建 AI 应用时,我们经常需要处理各种格式的文档和数据。文档解析节点解决了以下问题:
- 格式转换:将各种格式(PDF、DOCX、网页等)的文档转换为标准文本格式,方便后续处理
- 内容提取:从复杂文件中提取出有价值的文本内容
- 统一入口:为不同来源的数据(本地文件、网络内容、数据库等)提供统一的处理入口
- 预处理:对原始数据进行初步清洗和格式化,提高后续分析的质量
通过文档解析节点,您可以轻松将各种来源的数据转换为可供大模型理解和处理的文本形式,是构建知识问答、文档分析类应用的必备组件。
适用场景
场景一:知识库问答系统
将公司内部文档、产品手册、培训资料等导入并解析,结合大模型节点构建基于企业知识的问答系统,帮助员工快速获取所需信息。
场景二:网页内容分析
解析特定网页的内容,提取关键信息,用于市场分析、竞品监控或信息汇总。
场景三:文档智能处理
批量解析客户提交的文档(如简历、申请表等),提取关键信息并进行自动化处理和分类。
节点参数说明
输入参数
文档解析节点主要有以下输入参数:
| 参数名称 | 说明 | 是否必填 | 默认值 |
|---|---|---|---|
| 文件列表 | 需要解析的文件列表,可以是本地上传的文件、网络 URL 或变量引用 | 是 | 无 |
输出变量
文档解析节点会输出以下变量,可在后续节点中使用:
| 变量名 | 说明 | 示例值 |
|---|---|---|
| 全部内容(content) | 解析后的文本内容 | "这是一份产品说明书,包含以下特点..." |
| 文件(file_info) | 文件的基本信息,包括文件名、文件地址、内容、类型等 | {"name": "产品手册.pdf", "size": 1024, "type": "application/pdf"} |
使用说明
基本配置步骤
- 添加文档解析节点
- 配置文件来源
- 选择"文件上传"可上传本地文件
- 选择"网络 URL"可输入网页地址
- 选择"变量"可使用之前节点输出的文件数据
- 连接下游节点 将文档解析节点的输出连接到后续处理节点,例如文本切割节点、大模型调用节点等
进阶技巧
- 批量文件处理
- 动态 URL 解析
- 结合循环节点
- 条件解析
注意事项
文件大小限制
Magic Flow 平台对上传文件有大小限制,通常不超过 50MB。对于更大的文件,建议分割后上传或使用 URL 方式引入。
文件格式支持
虽然文档解析节点支持多种格式,但不同格式的解析效果可能有差异:
- PDF 文档:支持文本提取和表格识别
- Word 文档:支持完整文本和格式提取
- 网页内容:支持 HTML 解析,但复杂 JavaScript 渲染的内容可能无法完全获取
- 图片文件:需要通过 OCR 提取文字,准确率受图片质量影响
网络资源访问
通过 URL 解析网络内容时,请确保:
- URL 是可公开访问的
- 内容不需要登录验证
- 资源不违反版权和法律法规
性能考虑
解析大型文档或复杂格式可能需要较长时间,建议:
- 适当设置超时时间
- 对大文档进行预处理或分割
- 避免在一个流程中解析过多文件
常见问题
问题一:文档解析失败或内容缺失
可能原因:文件格式不兼容、文件损坏或加密、OCR 识别失败 解决方案:
- 检查文件是否可以正常打开
- 尝试将文件转换为更通用的格式(如 PDF 转 TXT)
- 对于加密文档,需要先解除加密后再上传
- 提高图片质量或调整 OCR 参数
问题二:解析时间过长
可能原因:文件过大、格式复杂、网络资源加载慢 解决方案:
- 分割大型文档为多个小文件
- 增加超时时间设置
- 对于网络资源,可以先下载到本地再上传解析
- 简化处理流程,只提取必要内容
问题三:特殊格式无法解析
可能原因:非标准格式、新版本格式、专业软件格式 解决方案:
- 将文件转换为标准格式后再上传
- 使用专业软件导出为兼容格式
- 结合代码节点自定义解析逻辑
- 联系平台支持团队寻求技术帮助
常见搭配节点
文档解析节点通常与以下节点配合使用:
- 文本切割节点:将解析出的长文本切割为适合大模型处理的片段
- 向量存储节点:将解析的文档内容转换为向量并存储,用于后续相似度搜索
- 大模型调用节点:使用大模型对解析的内容进行分析、总结或问答
- 代码节点:对解析结果进行自定义处理和转换
- 条件节点:根据解析结果的不同特征,选择不同的处理路径