大模型调用节点
什么是大模型调用节点?
大模型调用节点是 Magic Flow 工作流中的核心节点,它允许您直接与大型语言模型(如 GPT-4 等)进行交互,用于生成文本内容、回答问题、分析内容或进行推理。简单来说,这个节点就像是您在 Magic 平台上与人工智能对话的桥梁。
图片说明:
大模型调用节点界面包括模型选择、系统提示词、用户提示词等核心配置区域,以及高级配置选项如模型参数调整、知识库配置等。 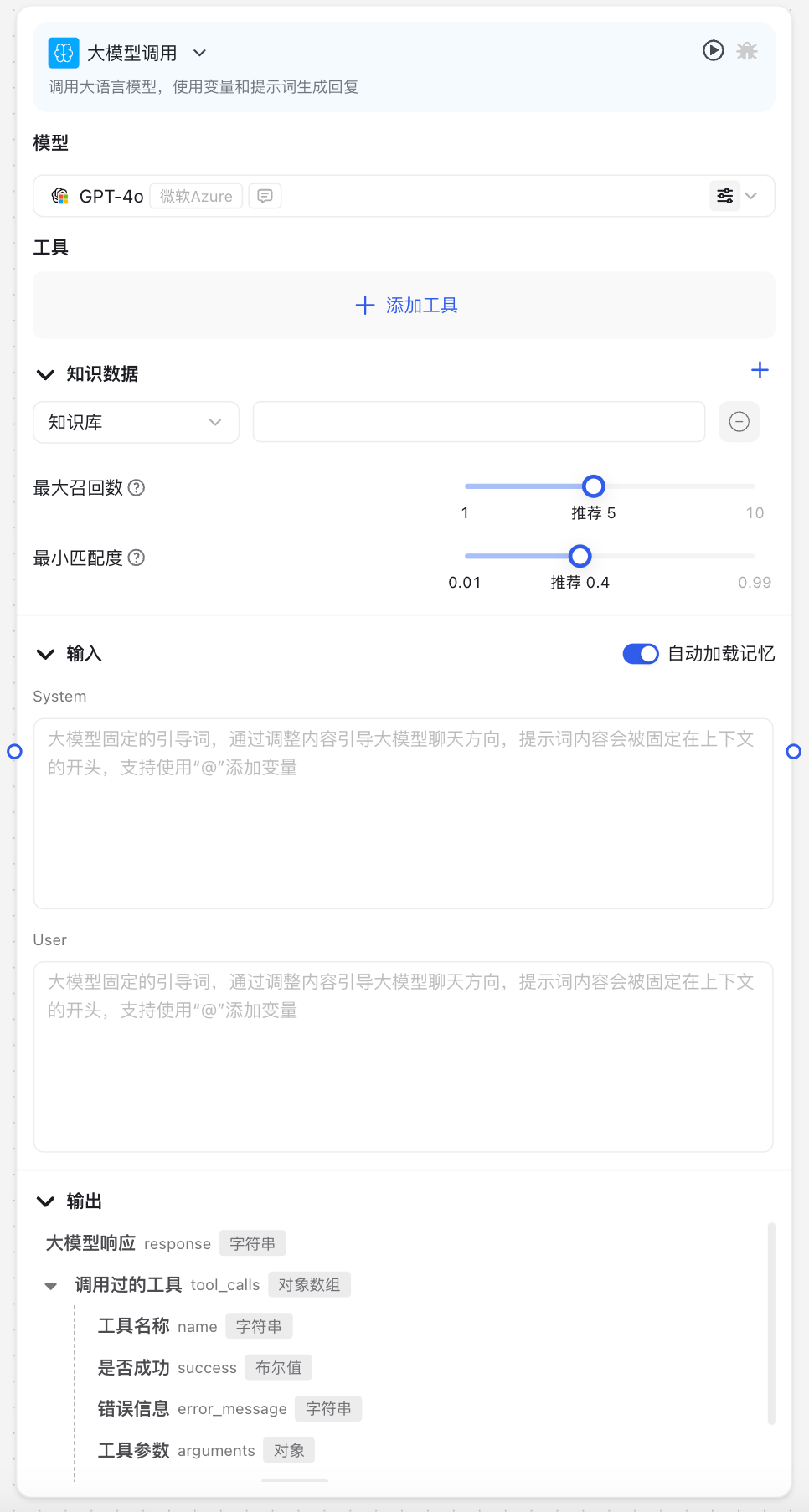
为什么需要大模型调用节点?
在智能应用的构建过程中,大模型调用节点充当"大脑"的角色,为您的工作流提供智能决策和内容生成能力:
- 自然语言处理:理解和生成人类语言,使应用能够以自然方式与用户交流
- 内容创作:生成文案、摘要、翻译或其他创意内容
- 知识问答:根据配置的知识库回答专业领域问题
- 逻辑推理:分析信息并得出结论,协助决策制定
- 个性化交互:根据用户需求和历史记录提供定制化的回复
适用场景
1. 智能客服机器人
设计一个能够回答产品咨询、解决用户问题的客服机器人,通过配置专业知识库,提供准确的产品信息和解决方案。
2. 内容创作助手
构建一个能够生成各类文案、摘要或创意内容的助手,如营销文案、产品描述或社交媒体帖子。
3. 知识库问答系统
创建基于企业内部文档的问答系统,让员工能快速获取专业信息,提高工作效率。
4. 数据分析与解读
将数据分析结果转化为易于理解的自然语言解释,帮助非技术人员理解复杂数据。
节点参数说明
基本参数
| 参数名称 | 说明 | 是否必填 | 默认值 |
|---|---|---|---|
| 模型 | 选择要使用的大语言模型,如 GPT-4、Claude 等 | 是 | gpt-4o-global |
| 工具 | 配置关联的工具能力,让模型基于特定知识回答 | ||
| 知识库设置 | 配置关联的知识库,让模型基于特定知识回答 | 否 | 无 |
| 系统提示词 | 给模型的背景指令,定义模型的角色和整体行为 | 是 | 无 |
| 用户提示词 | 用户的具体问题或指令 | 否 | 无 |
模型配置
| 参数名称 | 说明 | 是否必填 | 默认值 |
|---|---|---|---|
| 温度 | 控制输出的随机性,值越大回答越具创造性,值越小回答越确定性 | 否 | 0.5 |
| 自动加载记忆 | 是否启用自动记忆功能,记住对话历史 | 否 | 是 |
| 最大记忆条数 | 记忆的最大历史消息数量 | 否 | 50 |
| 视觉理解模型 | 用于处理图像的大模型名称 | 否 | 无 |
| 历史消息 | 设置历史对话消息,用于构建对话上下文 | 否 | 无 |
输出内容
| 输出字段 | 说明 |
|---|---|
| 大模型响应(response) | 大模型的回复内容,可用于显示给用户或传递给下游节点 |
| 调用过的工具(tool_calls) | 模型调用的工具信息,包含工具名称、参数、结果等 |
使用说明
基本配置步骤
- 选择合适的模型:
- 根据需求选择相应的大语言模型
- 一般任务可选择普通模型,复杂任务可选择高级模型如 GPT-4
- 编写系统提示词:
- 明确定义模型的角色,如"你是一位客服专员"
- 设定回答的风格和范围
- 告知模型可以使用的资源或工具
- 配置用户提示词:
- 可直接输入固定的问题或指令
- 也可使用变量引用动态内容,如
引用用户的实际输入
- 设置模型参数:
- 调整温度以控制回答的创造性或准确性
- 设置是否启用自动记忆和历史记录数量
- 配置知识库(可选):
- 选择要关联的知识库
- 设置相似度阈值和搜索结果数量
进阶技巧
提示词优化
编写高质量的提示词是有效使用大模型的关键:
- 明确具体:清晰表达您的期望和需求
- 角色设定:在系统提示词中给模型明确的角色定位
- 步骤拆分:引导模型按步骤思考复杂问题
与其他节点协同
- 搭配消息回复节点:
- 将大模型的输出通过消息回复节点展示给用户
- 设置用户提示词为空,让用户的消息自动作为输入
- 结合条件分支节点:
- 使用意图识别节点分析用户意图
- 根据不同意图转向不同的处理流程
- 配合知识检索节点:
- 先使用知识检索获取相关信息
- 再将检索结果作为上下文提供给大模型
注意事项
Token 限制
每个模型都有最大 token 处理限制,超出限制会导致错误:
- GPT-3.5:最多支持 16K tokens
- GPT-4:最多支持 128K tokens
- Claude:最多支持 200K tokens
知识时效性
大模型的知识有训练截止日期,对于最新信息可能不了解,建议:
- 对于需要最新信息的场景,考虑结合 HTTP 请求节点获取实时数据
- 或通过知识库定期更新最新信息
敏感信息处理
大模型可能会处理用户提供的信息,注意:
- 避免在提示词中包含机密或敏感信息
- 对于需保密的数据,建议使用知识库而非直接输入
常见问题
问题 1:大模型回复内容不符合预期怎么办?
解决方案:可能是提示词不够明确。尝试:
- 修改系统提示词,更具体地定义任务和期望
- 增加示例,展示理想的问答模式
- 调整温度参数,降低温度使回答更确定性
问题 2:如何处理大模型无法回答的专业问题?
解决方案:大模型依赖训练数据,对特定领域可能知识有限:
- 配置专业知识库,提供领域知识支持
- 在系统提示词中加入必要的背景知识
- 使用"查无信息则明确告知"的指令,避免编造答案
问题 3:大模型调用节点执行很慢怎么办?
解决方案:影响速度的因素有多种:
- 尝试使用响应更快的模型(如 GPT-3.5 替代 GPT-4)
- 减少历史消息数量,降低处理负担
- 优化提示词,使指令更简洁明确
最佳实践
常见搭配节点
| 节点类型 | 搭配原因 |
|---|---|
| 消息回复节点 | 将大模型生成的内容发送给用户 |
| 条件分支节点 | 根据大模型的输出决定下一步操作 |
| 知识检索节点 | 提供专业领域知识支持 |
| 历史消息查询 | 提供对话上下文,增强连贯性 |
| 变量保存节点 | 保存重要信息供后续流程使用 |