Data Loading Node
What is a Data Loading Node?
The Data Loading Node is a tool used to read previously stored data from a persistent database. It acts like a smart retriever that can quickly find and extract information previously saved in a persistent database based on the "data key" you provide, for use by other nodes in the workflow.
Image Description:
The Data Loading Node interface primarily consists of a query condition area, including scope selection, data key input field, and other key elements. Users can retrieve previously stored data from the persistent database by configuring these parameters. 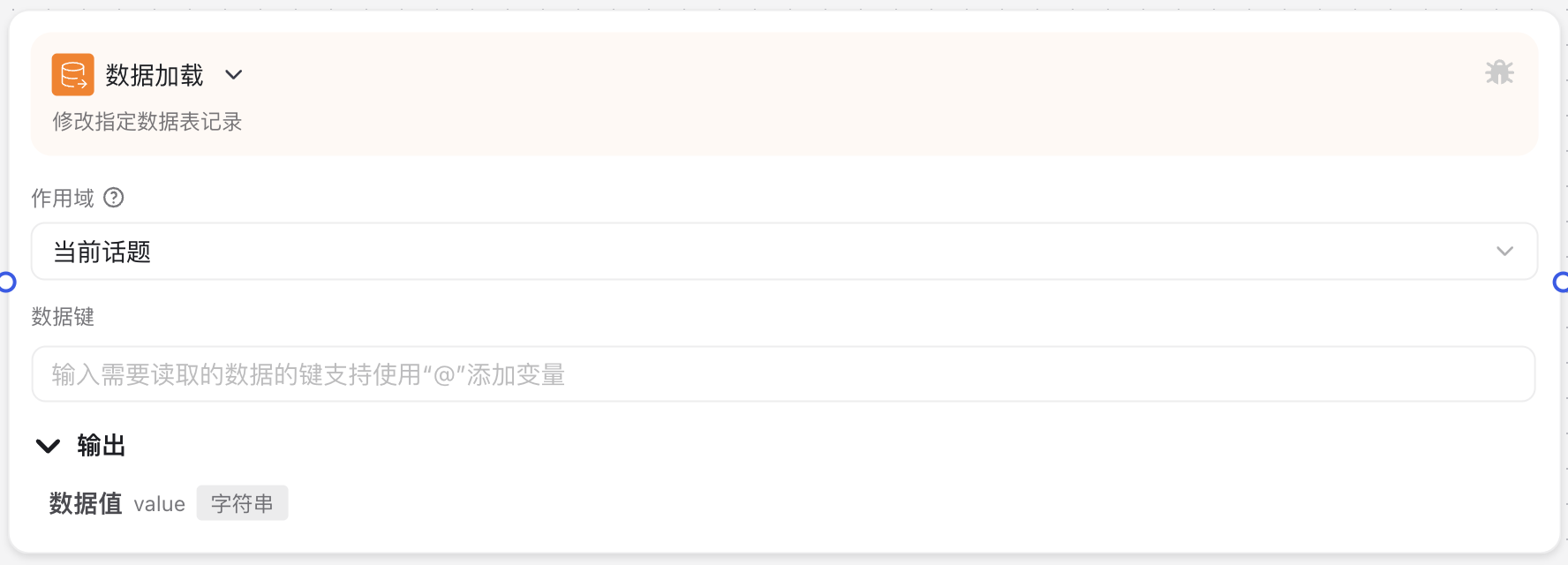
Why do you need a Data Loading Node?
In intelligent workflows, there is often a need to transfer and use data across different times or different sessions. For example:
- Remember user preferences and use them directly in the next conversation
- Store key information from the last interaction for subsequent processing
- Save business data, allowing retrieval and use at any time in the future
The Data Loading Node is designed to address this need, allowing you to conveniently retrieve any previously stored information, establishing a "long-term memory" capability for the workflow, giving the AI assistant persistent data access capabilities.
Application Scenarios
The Data Loading Node is suitable for the following scenarios:
- User Setting Memory: Read user preferences, usage habits, and other information to provide personalized services
- Business Process Continuity: Maintain business continuity across multiple conversations, such as reading information about previously unfinished orders
- Knowledge Retrieval: Read previously saved specialized knowledge or rules from persistent storage
- User Identity Recognition: Read user identity information for subsequent permission control and personalized services
Node Parameter Description
Input Parameters
| Parameter Name | Parameter Description | Required | Default Value | Notes |
|---|---|---|---|---|
| Scope | The storage range of the data | Yes | Current Topic | Determines which range to look for data in, available ranges include: Current Topic, Global, etc. |
| Data Key | The identifier of the data to be read | Yes | None | A unique identifier used to find data, supports using variables, such as "@UserID" |
Output Parameters
After successful execution, the Data Loading Node will output the following variables, which can be used in subsequent nodes:
| Output Variable Name | Data Type | Description |
|---|---|---|
| Value (value) | String/Array | Depending on the data type at storage time, this could be a simple text string or a complex JSON object or array |
Usage Instructions
Basic Configuration Steps
- Select Scope: Choose the data scope to query from the dropdown menu, usually with options like "Current Topic", "Current User", etc.
- Set Data Key: Enter the identifier of the data to be read in the "Data Key" input box
- You can directly input text, such as "UserPreferences"
- You can also click the "@" button to select a variable from the variable list as the data key
- Connect Subsequent Nodes: Connect the output of the Data Loading Node to subsequent nodes that need to use the data
Advanced Techniques
- Dynamic Data Keys: When you need to read different data based on different situations, you can use variables as data keys. For example, you can use "@UserID" as a data key, and the system will automatically read the corresponding data based on the current user ID.
- Combined with Conditional Judgment: After loading data, you can use conditional judgment nodes to check whether the data exists and is valid, thereby building more complex logical flows.
- Data Transformation: If the data read is in JSON format, you can use code nodes for parsing and conversion to extract specific fields.
Precautions
Handling Non-existent Data
When the data key to be read does not exist in the database, the Data Loading Node will output an empty value. In subsequent nodes, it is recommended to first check whether the value is empty to avoid process errors due to non-existent data.
Data Expiration Issues
If an expiration time was set when the data was stored, the data will automatically become invalid after that time. Please ensure appropriate alternative processing plans are in place in case the data may expire.
Data Type Consistency
The Data Loading Node will return data of the same type as when it was stored. For example, if a JSON object was stored, a JSON object will also be obtained when loading. Please ensure that subsequent nodes can correctly process that type of data.
Frequently Asked Questions
Question 1: Why can't I read the previously stored data?
Possible reasons:
- Data key name is incorrect or inconsistently spelled
- Wrong scope selection (e.g., data stored in "Global" scope but trying to read from "Current Topic")
- Data has expired (if an expiration time was set during storage)
- Data may have been deleted or overwritten by other processes
Solutions:
- Confirm that the data key name is exactly the same as when it was stored
- Check if the scope is the same as when it was stored
- If you suspect the data has expired, try storing it again first
- Add log or debug nodes after the Data Loading Node to check the loading results
Question 2: How to determine if data was successfully loaded?
Solution:
Add a conditional judgment node after the Data Loading Node to check if the output value is empty. If it's not empty, then the data was successfully loaded; if it's empty, then the data may not exist or has expired.
Common Node Combinations
| Node Type | Combination Reason |
|---|---|
| Conditional Judgment Node | Make judgments after loading data to decide subsequent process |
| Code Execution Node | Process and transform complex data after reading |
| Large Model Call Node | Pass loaded data as context to the large model, enhancing the relevance of model answers |
| Data Storage Node | First use the Data Storage Node to save data, later use the Data Loading Node to read it |