Knowledge Retrieval Node
What is a Knowledge Retrieval Node?
The Knowledge Retrieval Node is a powerful semantic search tool that can find relevant content in specified knowledge bases based on user input keywords. This node utilizes vector similarity matching technology to help you quickly locate needed knowledge fragments, achieving efficient knowledge retrieval and application.
Image Description:
The Knowledge Retrieval Node interface mainly includes knowledge base selection area, retrieval parameter setting area, and output configuration area. In the middle, you can select knowledge base sources and set parameters like similarity threshold and maximum count. 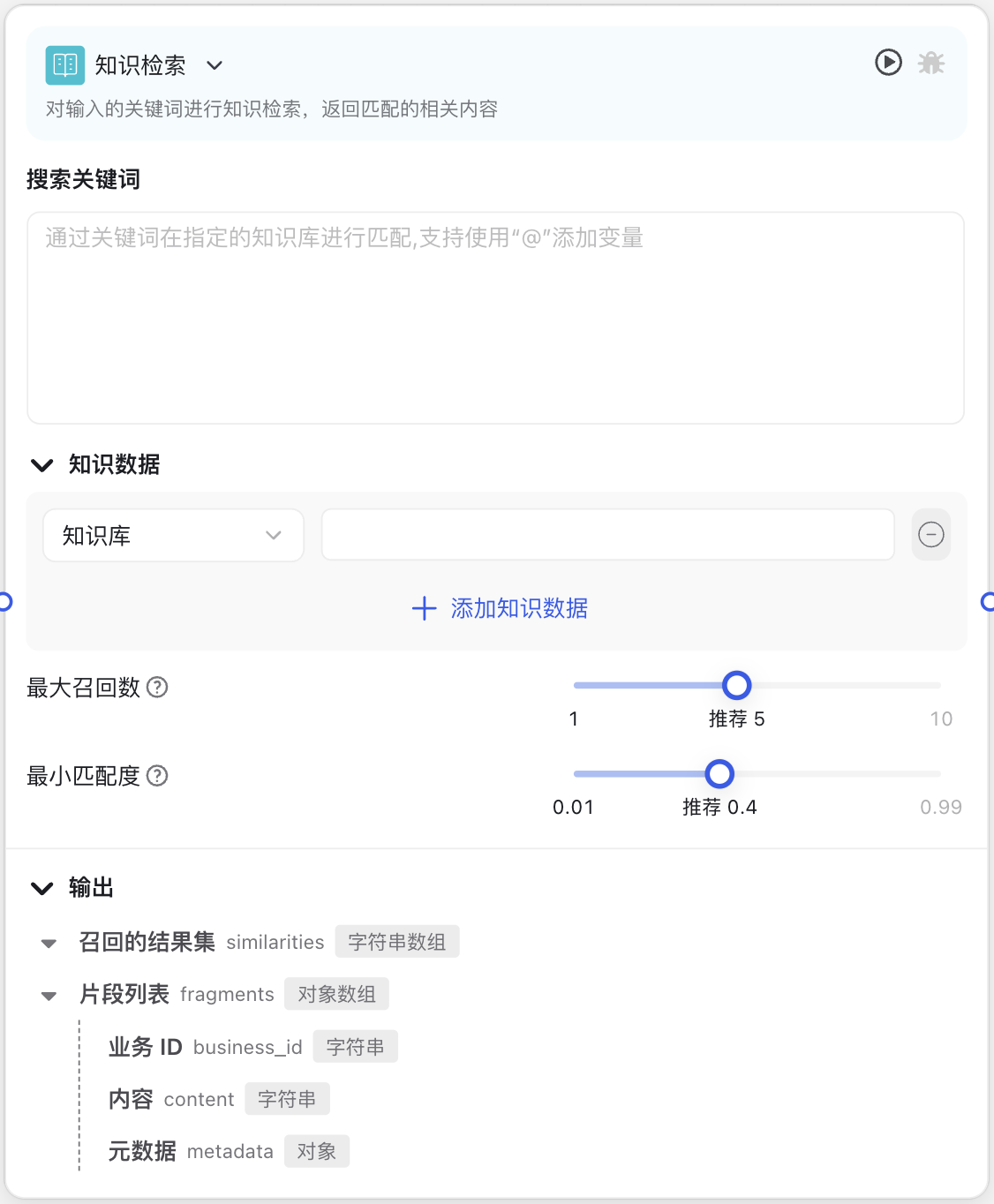
Why Do We Need Knowledge Retrieval Node?
In building intelligent applications, the Knowledge Retrieval Node solves the following key issues:
- Professional Knowledge Access: Enable AI to access and use internal professional materials, documents, or knowledge
- Improve Answer Accuracy: Provide more accurate and professional answers through retrieving relevant information, reducing "imagined" or outdated answers
- Knowledge Timeliness: Access the latest updated knowledge content, solving the knowledge cutoff date limitation of large models
- Personalized Content: Provide targeted professional knowledge answers based on specific user needs
- Reduce Training Costs: No need to retrain models for each new knowledge, just update the knowledge base
Application Scenarios
1. Enterprise Internal Knowledge Q&A System
Build an internal assistant that can answer questions about company policies, processes, product information, etc., helping new employees quickly understand company information or assist existing employees in checking latest regulations.
2. Professional Customer Service Bot
Create a customer service bot that can accurately answer product questions, troubleshooting, usage guides, and other professional questions, improving customer service quality and efficiency.
3. Document Intelligent Assistant
Design an intelligent assistant that can understand and answer questions about specific document content, such as product manual interpretation, contract clause explanation, research report analysis, etc.
4. Learning Assistance System
Build a learning assistance system that can answer study questions and provide knowledge explanations based on educational materials, helping students better understand complex concepts.
Node Parameter Description
Basic Parameters
| Parameter Name | Description | Required | Default Value |
|---|---|---|---|
| Knowledge Base | Select knowledge base(s) to search, can select one or multiple | Yes | None |
| Search Keywords | Keywords or questions for searching related content | Yes | None |
| Minimum Match Score | Set minimum similarity requirement for knowledge matching, range 0~1 | - | 0.4 |
| Maximum Return Count | Maximum number of results to return | - | 5 |
Advanced Parameters
Output Content
| Output Field | Description |
|---|---|
| Fragment List (fragments) | List of retrieved knowledge fragments, including content and similarity information |
| Recall Result Set (similarities) | List of similarity scores for each fragment |
| total_count | Total number of retrieved knowledge fragments |
Usage Instructions
Basic Configuration Steps
- Select Knowledge Base:
- Click knowledge base dropdown to select one or multiple knowledge bases to search
- Can select public knowledge bases or self-created private knowledge bases
- Set Search Keywords:
- Input search keywords or questions
- Can input fixed text directly, like "What is the company's annual leave policy?"
- Can also use variables to reference dynamic content, like
to reference actual user questions
- Adjust Minimum Match Score:
- Drag slider to set similarity threshold (between 0.01 and 0.99)
- Higher value requires more precise matching but might miss related content
- Lower value includes more related content but might include less relevant results
- Set Maximum Return Count:
- Set maximum number of results to return based on needs
- Recommend 3-5 items, providing sufficient information without being excessive
Advanced Tips
Optimize Retrieval Effects
- Improve Retrieval Precision:
- Use clear, specific questions rather than broad keywords
- Increase similarity threshold (e.g., above 0.7) for more precise matches
- Choose knowledge bases focused on specific topics rather than comprehensive ones
- Increase Retrieval Coverage:
- Search multiple related knowledge bases simultaneously
- Appropriately lower similarity threshold (around 0.5)
- Increase maximum return count
Collaboration with Other Nodes
- Pair with Large Model Call Node:
- Provide retrieval results as context to large model
- Let large model generate more accurate answers based on retrieved knowledge
- Combine with Conditional Branch Node:
- Check if related knowledge is found (fragments length > 0)
- If results exist, provide professional answer
- If no results, switch to general answer or human service
- Work with Variable Save Node:
- Save retrieval results for use by multiple subsequent nodes
- Avoid repeatedly retrieving same content, improving efficiency
Important Notes
Knowledge Base Quality
Retrieval effectiveness largely depends on knowledge base quality:
- Ensure knowledge base content is accurate, complete, and up-to-date
- Regularly update knowledge base, delete outdated information
- Appropriately categorize and tag knowledge content to improve retrieval precision
Retrieval Efficiency
Searching large knowledge bases may affect performance:
- Try to select knowledge bases most relevant to the question, rather than searching all
- Set reasonable maximum count to avoid returning too many unnecessary results
- Consider caching retrieval results for common questions to improve response speed
Privacy Security
Knowledge bases may contain sensitive information:
- Ensure correct access permission settings for knowledge bases
- Avoid exposing sensitive knowledge content in public scenarios
- Apply necessary content filtering to retrieval results
Common Issues
Issue 1: What If No Relevant Content is Retrieved?
Solutions:
- Try lowering similarity threshold, e.g., from 0.7 to 0.5
- Reorganize search question, use more keywords or more concise expression
- Check if knowledge base contains related content, update if necessary
- Consider selecting more related knowledge bases for search
Issue 2: Too Many Irrelevant Results in Retrieval?
Solutions:
- Increase similarity threshold, e.g., from 0.5 to 0.7 or higher
- Use more precise question descriptions
- Narrow knowledge base scope, select knowledge bases more focused on specific topics
- Reduce maximum return count
Issue 3: How to Handle Diverse User Questions?
Solutions:
- Use intent recognition node to analyze user question type first
- Select different knowledge bases based on different question types
- Configure different similarity thresholds and maximum counts
- Combine with large model to integrate and optimize retrieval results
Best Practices
Common Paired Nodes
| Node Type | Pairing Reason |
|---|---|
| Large Model Call Node | Provide retrieval results as context to large model, generate knowledge-based answers |
| Conditional Branch Node | Decide subsequent processing flow based on retrieval results |
| Message Reply Node | Reply processed knowledge content to users |
| Text Segmentation Node | Process overly long retrieval results, ensure suitability for subsequent processing |
| Variable Save Node | Save retrieval results for use by multiple nodes |