Data Storage Node
What is a Data Storage Node?
The Data Storage Node is a functional component in the Magic platform used for persistently saving key information. It's like a reliable notebook that can record important data in the workflow and access it whenever needed, retaining this information even after the conversation ends.
Image Description:
The Data Storage Node interface mainly includes four primary sections: scope selection area, data key input area, data value editing area, and expiration time setting area. Through the configuration of these areas, users can specify the data to be saved and how it is stored. 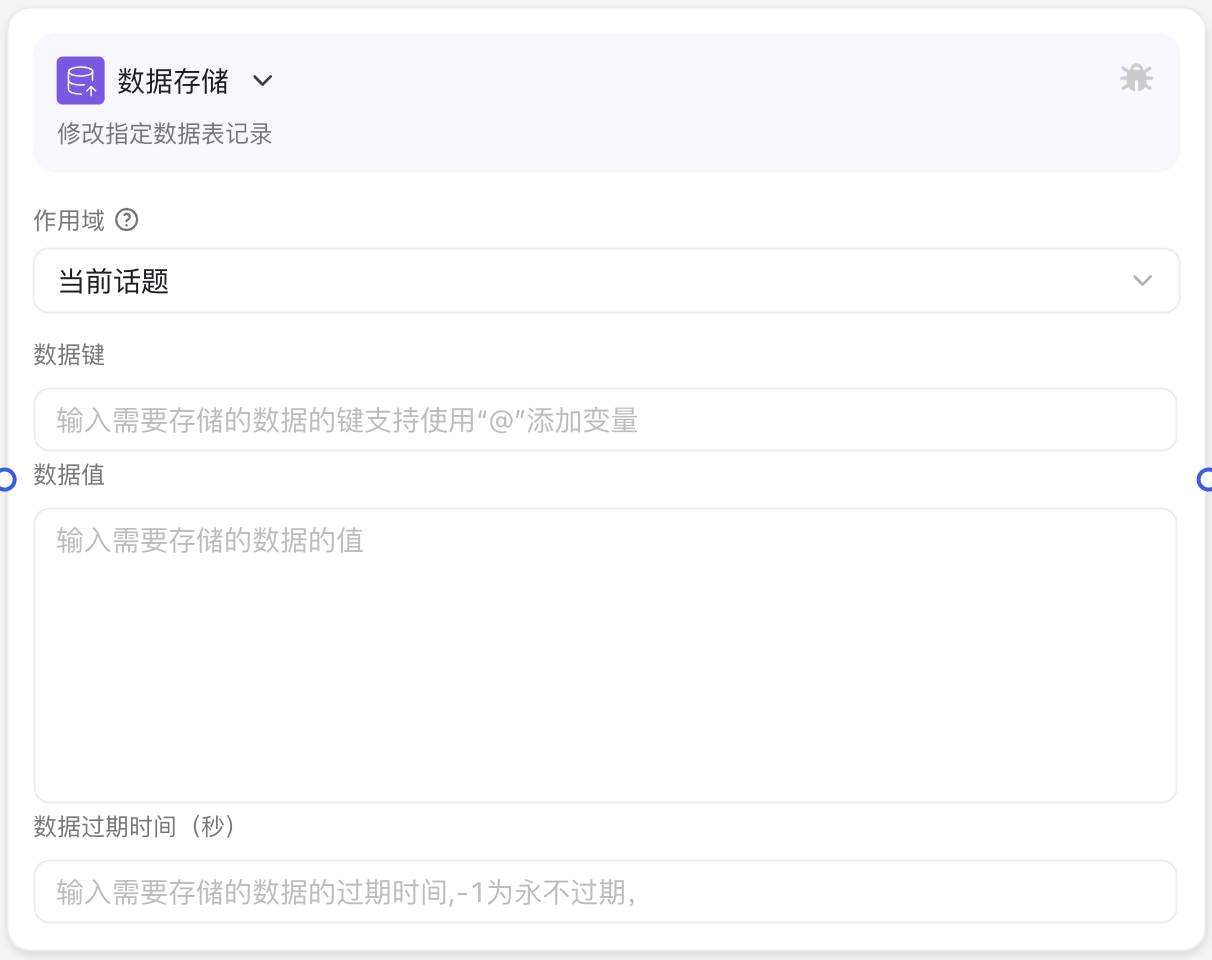
Why do you need a Data Storage Node?
In the process of using AI assistants, we often need to remember some important information for subsequent use, such as:
- Cross-session Memory: User preferences, historical interaction records, etc. that need to be stored long-term
- Data Persistence: Saving temporarily generated important data (such as analysis results, key information input by users)
- State Management: Recording the execution state of workflows, supporting breakpoint continuation of complex business processes
- Shared Information: Sharing data between different AI assistants or workflows
The Data Storage Node acts as the "long-term memory" of the AI assistant, giving it a "photographic memory" capability, greatly enhancing user experience and the practicality of AI assistants.
Application Scenarios
Scenario 1: User Information Memory
Remember personal information such as the user's name, preferences, etc., and directly call upon it in subsequent interactions without having to ask repeatedly, providing personalized service.
Scenario 2: Multi-round Dialogue Context Preservation
In the process of solving complex problems, save intermediate results or discussion points so that even after the conversation is interrupted and restarted, you can quickly return to the previous discussion state.
Scenario 3: Business Status Tracking
In the business process, record which step the user has reached, so that they don't have to start from the beginning when continuing to process the next time.
Node Parameter Description
Input Description
| Parameter Name | Description | Required |
|---|---|---|
| Scope | Select the storage range of the data, determining who can access this data. The default option is usually "Current Topic". | Yes |
| Data Key | Used to identify the stored data, equivalent to the "name" of the data, facilitating subsequent lookup and use. Supports using "@" to reference variables. | Yes |
| Data Value | The specific content to be stored, which can be text, numbers, or data in other formats. Supports using "@" to reference variables. | Yes |
| Expiration Time (seconds) | Set the validity period of the data, after which the data will be automatically deleted. Leaving it blank indicates that the data never expires. Supports using "@" to reference variables. | No |
Output Description
The Data Storage Node will save the specified data to persistent storage but does not directly generate output variables. After saving successfully, you can retrieve the saved data using the same key name through the "Data Loading Node".
Usage Instructions
Basic Configuration Steps
- Add Data Storage Node: In the workflow editor, drag the Data Storage Node onto the canvas.
- Configure Scope: Select an appropriate scope, usually "Current Topic" can meet most requirements.
- Set Data Key: Specify a clear, meaningful name for the data to be stored, making it easier to identify later.
- For example:
user_preference,last_order_id, etc. - If you need to use a variable as the key name, you can click the "@" button to select an existing variable.
- For example:
- Fill in Data Value: Enter the specific content to be stored.
- It can be fixed text, such as
"Order completed". - It can also reference variables, such as
@user_response.
- It can be fixed text, such as
- Set Expiration Time (optional): Set an appropriate expiration time based on the usage scenario of the data.
- Temporary data can be set with a shorter time, such as
3600(1 hour). - Data for long-term use can be left blank (never expires) or set with a longer time.
- Temporary data can be set with a shorter time, such as
Advanced Techniques
- Dynamic Key Name Design:
- You can use variable combinations to generate dynamic key names, such as
user_@user_id, which creates dedicated data entries for different users. - Use key name prefixes with patterns, such as
temp_data_1,temp_data_2, for easier batch management of related data.
- You can use variable combinations to generate dynamic key names, such as
- Data Organization Optimization:
- For complex data, consider storing in JSON format, such as
{"name": "John", "age": 28}. - Use prefixes to distinguish different business data, such as
order_xxxanduser_xxx.
- For complex data, consider storing in JSON format, such as
Precautions
Data Key Naming Conventions
- Avoid Special Characters: Key names should primarily use letters, numbers, and underscores, avoiding parsing issues that may be caused by special characters.
- Maintain Uniqueness: Within the same scope, different data should use different key names, otherwise new values will overwrite old ones.
- Meaningful Naming: Use key names that reflect the data content to improve code readability, such as
user_ageis more intuitive thanu_a.
Data Storage Limitations
- Data Size Limitation: The size of a single data item should be controlled within a reasonable range (generally recommended not to exceed 10MB).
- Storage Capacity Consideration: Persistent storage has total capacity limitations, please plan usage reasonably and clear unnecessary data in a timely manner.
- Sensitive Information Handling: Avoid storing sensitive information such as user privacy; if it must be stored, ensure it is encrypted.
Frequently Asked Questions
What if I can't find the saved data?
Answer: Possible reasons include:
- Data key name spelling error: Check if the key name used when loading data is exactly the same as when it was stored.
- Different scope selection: Ensure that the same scope is selected when loading data as when it was stored.
- Data has expired: Check if the expiration time set during storage has been reached.
- Data has been overwritten by other processes: Keys with the same name will be overwritten by new values, check if other processes are using the same key name.
How to efficiently manage multiple related data items?
Answer: The following methods are recommended:
- Use naming prefixes: For example, all data keys related to users start with "user_".
- Adopt JSON format: Organize related data into JSON objects to store together, rather than storing them separately.
- Set reasonable expiration times: Set shorter expiration times for temporary data, automatically clearing data that is no longer needed.
Common Node Combinations
| Node Type | Combination Reason |
|---|---|
| Conditional Branch Node | Determine whether specific data exists based on data loading results, choosing different processing paths. |
| Large Model Call Node | Use stored context information to provide a more coherent dialogue experience. |