Start Node
What is a Start Node?
The Start Node is the beginning of a workflow, acting like a starting gun that determines when the workflow begins running and how it receives initial data. Every workflow must have a start node, which serves as the entry point for the entire process. The Start Node is primarily responsible for receiving system inputs (such as session information, message content), user information, and custom parameters, and passing these to subsequent nodes in the workflow.
Image Description:
The Start Node interface mainly consists of several parts: the top section contains the node title and trigger condition description; the middle area includes system inputs (such as session ID, topic ID, message content, etc.), file list, and user information; the bottom area supports configuration of custom system inputs and large model parameter inputs. Through these configurations, you can control the workflow's startup conditions and initial data.
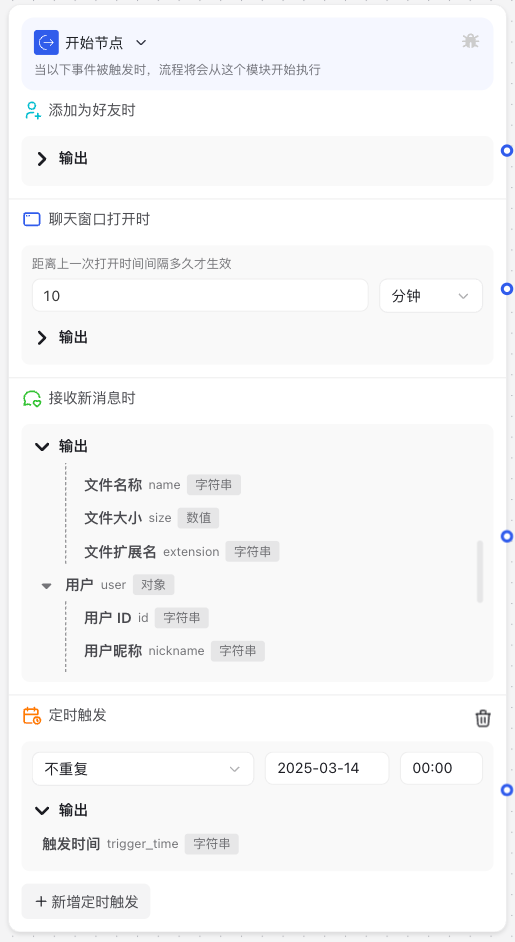
Why Do We Need a Start Node?
When building workflows, the Start Node is indispensable because it solves the following key problems:
- Determine Workflow Trigger Conditions: The Start Node clarifies when the workflow begins, such as when a user sends a message, on a scheduled trigger, or when called as a subprocess/tool.
- Receive and Format Initial Data: The Start Node is responsible for collecting initial data needed for workflow execution, such as user message content, user information, or other system data.
- Connect External World with Workflow: The Start Node serves as a bridge between external events (like user interactions) and the workflow system, ensuring data flows correctly into the workflow.
- Standardize Data Processing: The Start Node unifies the formatting of data from different sources, making it easier for subsequent nodes to process.
Application Scenarios
1. User Dialogue Trigger
When users send messages to the AI assistant, the Start Node receives the message content and related information, initiating the dialogue processing flow. This is the most common usage scenario, suitable for applications like Q&A assistants and customer service bots.
2. Scheduled Tasks
Configure the Start Node to trigger at specific times, executing regular workflow tasks such as data statistics, report generation, or regular reminders.
3. Subprocess and Tool Calls
When the main process needs to execute reusable subtasks, it can call subprocesses or tools with the Start Node as the entry point through parameters, passing data to achieve modular and reusable workflow components. Both subprocesses and tools support parameter calls, allowing you to build more flexible and reusable workflow components.
Node Parameter Description
System Input Parameters
System inputs are basic information automatically provided by the platform that you can directly use in the workflow:
| Parameter Name | Description | Data Type | Usage Notes |
|---|---|---|---|
| Session ID | Unique session identifier for user-AI assistant interaction | String | Used for identifying and managing dialogue context |
| Topic ID | Identifier for current conversation topic | String | Used for distinguishing different topics within the same session |
| Message Content | Text message sent by user | String | Main content for workflow processing |
| Message Type | Message type identifier | String | Such as text, image, etc. |
| Send Time | Message timestamp | String | Records message time information |
| Organization Code | Code of user's organization | String | Used for organization-level functions and permission management |
File List Parameters
When users upload files, you can access file-related information:
| Parameter Name | Description | Data Type | Usage Notes |
|---|---|---|---|
| File Name | Original name of uploaded file | String | Used for displaying and processing files |
| File Link | URL for accessing the file | String | Used for downloading or accessing file content |
| File Extension | File format suffix | String | Such as pdf, docx, xlsx, etc. |
| File Size | File size in bytes | Number | Used for file processing control |
User Information Parameters
Basic user information provided by the system, can be used for personalized processing:
| Parameter Name | Description | Data Type | Usage Notes |
|---|---|---|---|
| User ID | Unique user identifier | String | Used for user identification and data association |
| User Nickname | User's display name | String | Used for personalized interaction |
| Real Name | User's actual name | String | Used for formal addressing |
| Employee ID | User's ID within organization | String | Used for internal enterprise identification |
| Position | User's position in organization | String | Used for role-related functions |
| Department | User's department | String | Used for department-level functions and data |
Usage Instructions
Basic Configuration Steps
- Add Start Node:
- System automatically adds Start Node when creating new workflow
- For existing workflows, drag "Start Node" from node panel to canvas
- Configure Trigger Conditions:
- By default, Start Node triggers when receiving user message
- For scheduled triggers or other specific conditions, set in advanced options
- View System Inputs:
- Expand "System Inputs" section to understand available system parameters
- These parameters are automatically populated, no manual configuration needed
- Configure Custom Inputs (Optional):
- Click "Custom System Inputs" or "Large Model Parameter Inputs"
- Click "Add Parameter" button
- Set parameter name, display name, parameter type, and whether required
- Add parameter description to help understand parameter purpose
- Connect Next Node:
- Drag connection line from Start Node to next processing node
- Ensure workflow has clear execution path
Notes
Parameter Naming Convention
- Avoid Special Characters: Parameter names should use letters, numbers, and underscores, avoid spaces and special characters
- Avoid System Reserved Names: Don't use names same as system parameters, like "message", "user_id", etc.
- Naming Consistency: Maintain consistent naming style for easier maintenance and understanding
Data Type Matching
- Type Consistency: Ensure actual parameter data types match defined types
- Type Conversion: If different types needed, perform explicit conversion in subsequent nodes
- Complex Data Structures: For object or array types, understand internal structure before using
Trigger Condition Control
- Avoid Frequent Triggers: For scheduled processes, set reasonable time intervals
- Condition Precision: Ensure trigger conditions precisely match business requirements, avoid unnecessary triggers
- Test Verification: Fully test trigger conditions before deployment, ensure they meet expectations
Common Issues
Why aren't my custom parameters taking effect?
- Check Parameter Names: Confirm parameter names are spelled correctly, case-sensitive
- Check Data Types: Confirm provided data matches defined parameter types
- Check Required Fields: Confirm all required parameters have values
- Check Reference Method: In subsequent nodes, ensure parameters are correctly referenced (using
${parameter_name}format)
How to use multiple start nodes in one workflow?
- Use Conditional Branches: Use conditional branch node immediately after Start Node, different branches based on different input conditions
- Create Multiple Subprocesses/Tools: Create independent subprocesses or tools for different entry scenarios, then call through parameters in main workflow
- Use Wait Node: Use wait node in workflow to allow receiving new triggers at different points
Why isn't my workflow executing despite setting trigger conditions?
- Check Switch: Check if workflow is published and enabled
- Confirm Trigger Time: Adjust trigger condition time interval
- Check Permission Settings: Confirm system permission settings